Regulatory Intelligence Transformed
At Redica, we used GPT-4o and a knowledge graph to turn fragmented pharma regulatory data into real intelligence. We built a system that connected guidance, inspections, enforcement actions, and CFRs so users could actually navigate it. I used GPT-4o to extract relationships, summarize documents, translate non-English content, and surface links others missed. Users could chat with any document, auto-generate site risk briefings, and explore complex topics without slogging through PDFs. The result: faster answers, clearer context, better decisions.
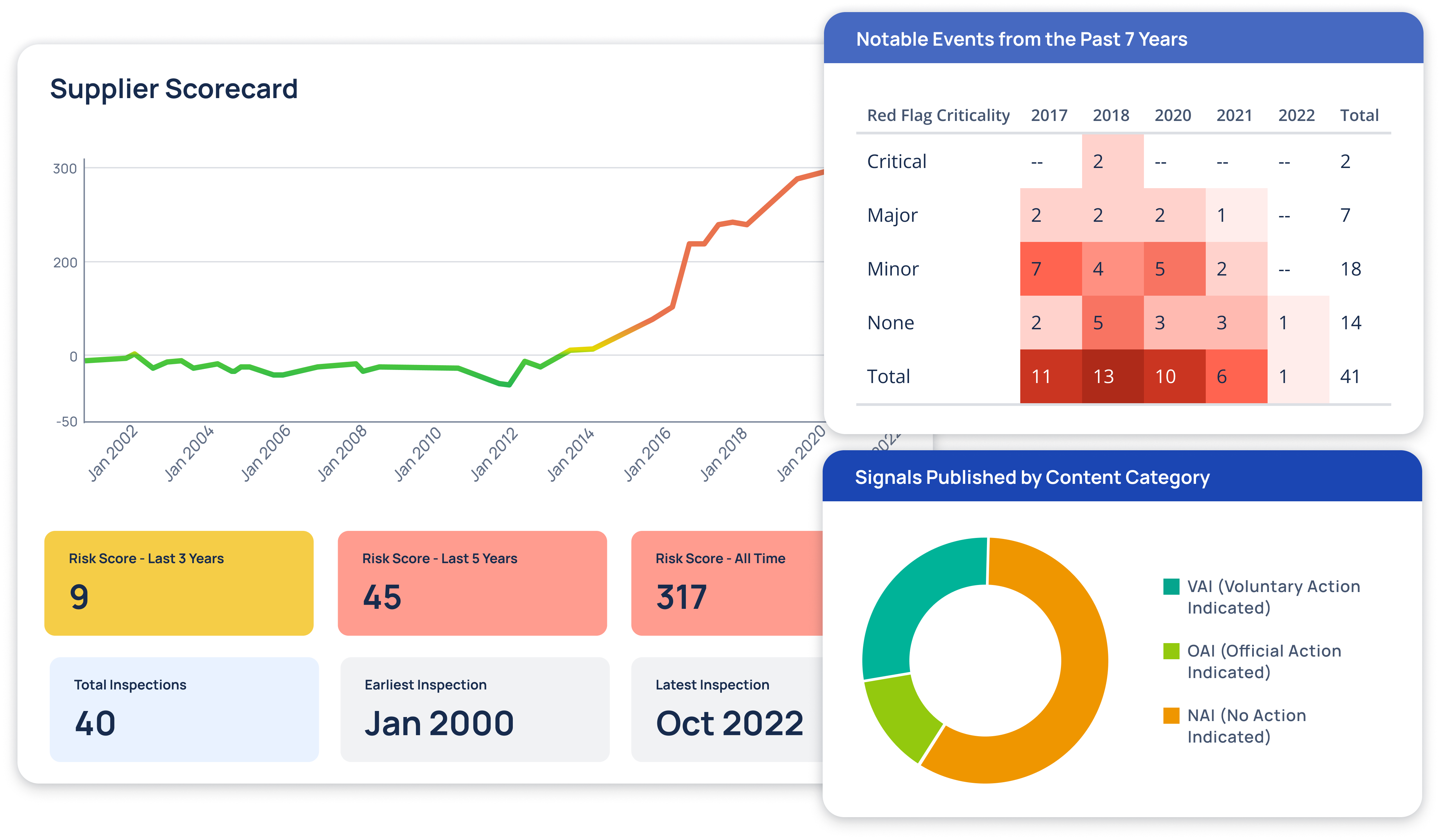
Supplier Risk Intelligence
Real-time tracking of regulatory events and risk patterns across pharmaceutical suppliers
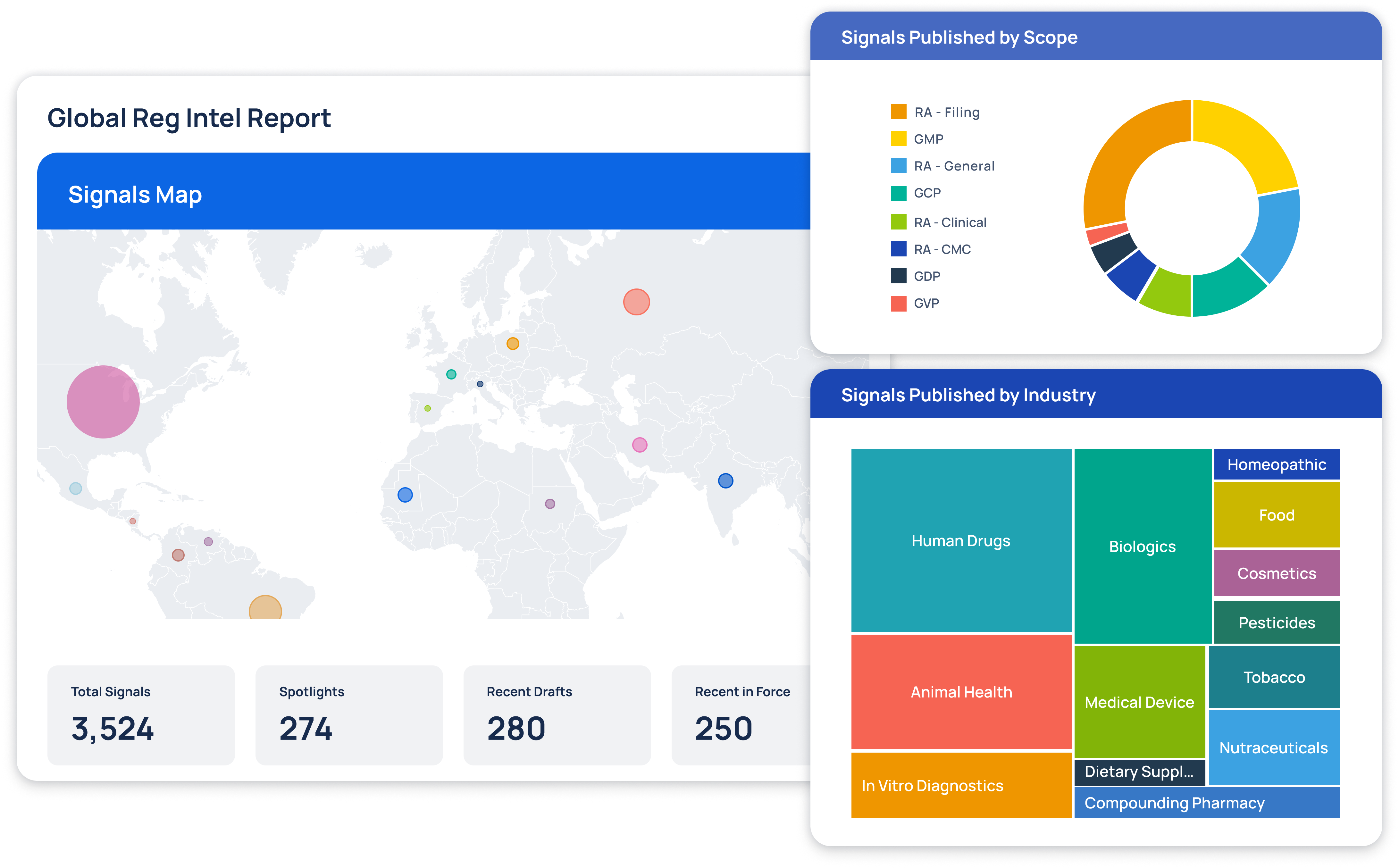
Global Regulatory Intelligence
Interactive mapping of regulatory signals across regions, industries, and compliance categories
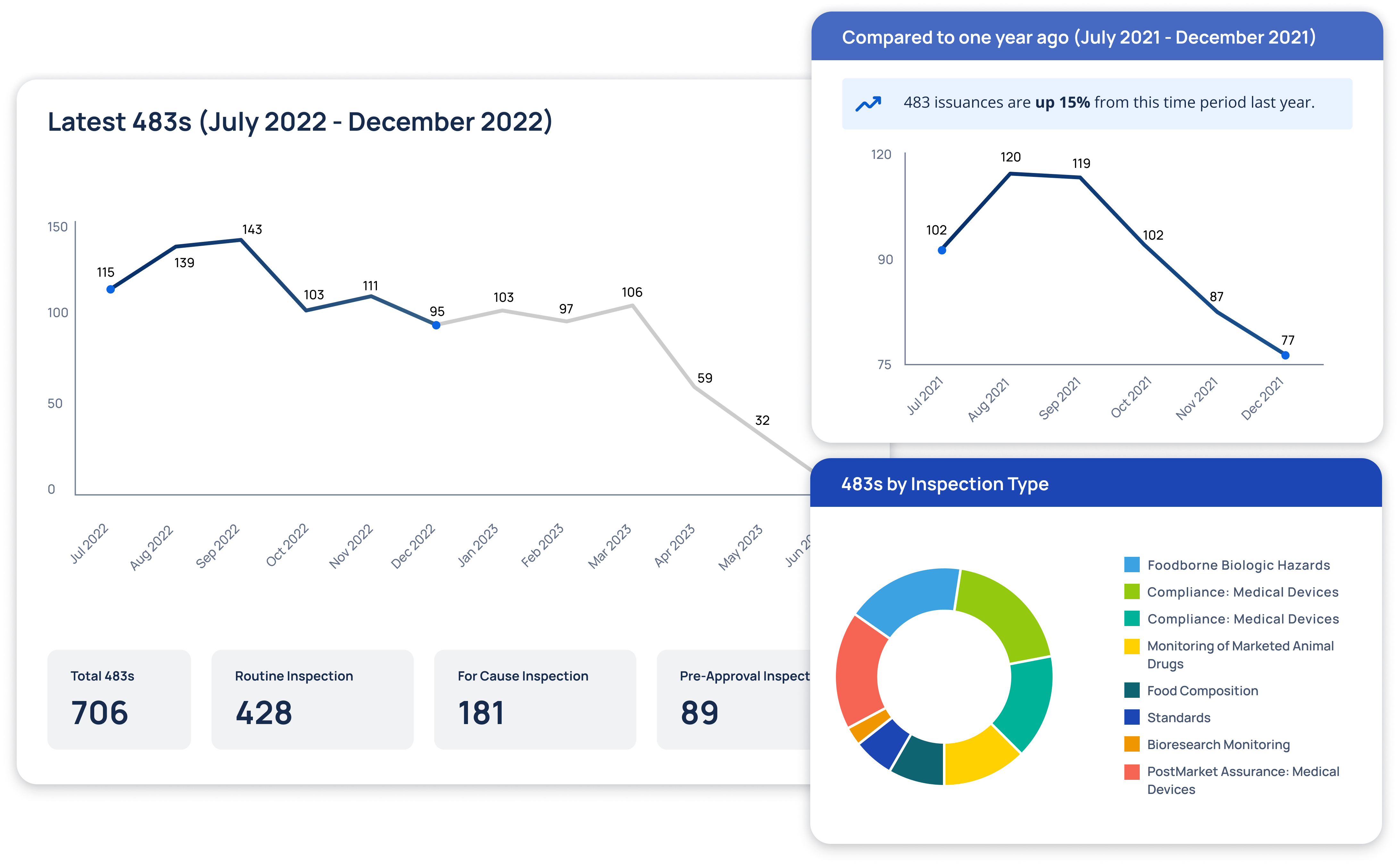
Inspection Trends & Patterns
Advanced analytics revealing inspection patterns, compliance trends, and predictive risk indicators